DNA extension for ABCD - General information & installation manual |
|
|
Another BioCASE wrapper on all connected databases had to be
installed mandatory to offer DNA samples and its related
specimen data on the central webportal (www.dnabank-network.org).
Although the
ABCD 2.06 schema (part of the BioCASE wrapper) is currently
preferred its existing part for DNA ‘Sequences’ lacks important
features. So, it shouldn’t be used any longer. The whole ABCD
2.06 schema is available
here. If you want to learn more about the meaning of BioCASe
and ABCD please follow the links. ABCD offers two options to add supplementary contents: ‘MeasurementsOrFacts’ and ‘UnitExtensions’. Since the hierarchical structure of DNA specific features is too complex for ‘MeasurementsOrFacts’ we decided to use ‘UnitExtensions’ to integrate an xml schema definition for DNA data similar to the ABCDEFG extension for geosciences. That new DNA extension for ABCD 2.06 is called ABCDDNA. The DNA Sample means ABCD Unit and the identifier (Triple ID) for the related specimen is defined by ‘UnitAssociation’. Please read the following manual for using the schema within the BioCASe provider software and have a look at a mapping example.
|
|
Using ABCDDNAThe basic ABDC 2.06 version is remains unmodified. The new created DNA schema covers more than 35 elements such as “ExtractionDate”, “ExtractionMethod” for DNA extraction as well as an “Amplification-Container” for Sequences, GenBankNumbers, CloneStrain etc.-> View ABCDDNA schema:
html or
xml. The following requirements have to be met to
use the schema: |
|
1. Installation of BioCASe Provider Software (Download section).The installation is documented here.Note: If the software package DiGIR is already implemented on your specimen database it is possible to run both installations in parallel! |
|
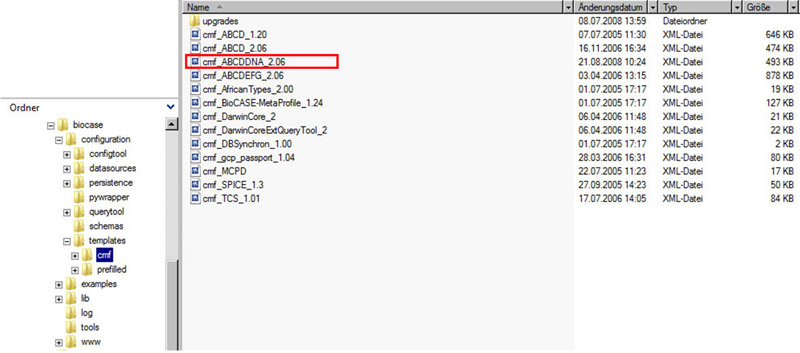
2. Installation of ABCDDNA-TemplateThe current BioCASe Provider Software package does not include this template! It requires a cm file which can be downloaded form the website of the DNA Bank Network – Download section. Please copy it into the template folder of your BioCASe installation.Version 2.4.2:
your_biocase2.4.2_folder/configuration/templates/cmf/ |
|
 |
|
|
Fig. 4. Copy the cm file into your BioCASe cmf folder. |
|
3. Creating a new datasourceIf you want to use the ABCDDNA schema for mapping you have to create a new datasource connection. You can use the BioCASe documentation for assistance or contact Gabi Droege (g.droege@bgbm.org).After you have created a new datasource you have to declare the database connection and the database structure. Then you can select a schema (ABCDDNA) and click on “Create”. |
|
4. Mapping the DNA databaseThe first time you open the mapping page only few fields are visible. Select “Show all concepts” and press “Refresh” to see all available features.Since the DNA sample means ABCD Unit the Triple Identifier (composed of UnitID, SourceInstitutionID and SourceID) has to map as follows: UnitID → DNA Bank Number (unique DNA Number in your database but NOT the ID in the DNA table) SourceInstitutionID → Code or abbreviation of the institution the DNA bank is located, e.g. BGBM for Botanic Garden and Botanical Museum Berlin-Dahlem SourceID → Designation of the collection, e.g. DNA bank Note: Please don’t map DNA data only. To verify the related specimen it is absolutely essential to map both the identification part (Taxon Name) and the UnitAssociation. It is furthermore advantageous to map few gathering attributes such as CountryName or ISO-Code.
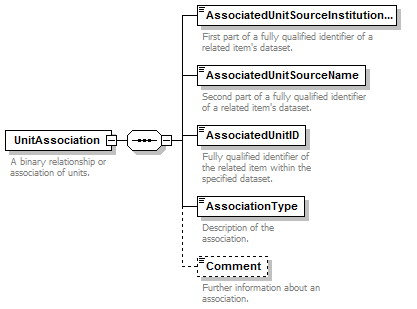
UnitAssociation
(Triple Identifier of the related specimen): These three listed attributes of the 'UnitAssociation' and
the Triple Identifier used in the original specimen database
should have the same values. They can than be used as GUIDs (Globally
Unique Identifier) since both values describe the same
specimen. |
|
|
Example: |
|
|
Note: Please pay attention to special characters like µ, ä, ö, ü, ß! They have to be translated into Unicode. E.g. a common mistake is to complete the field Unit@Concentration with “ng/µl” when “ng/ µl” should be used instead. It is no problem if special characters are used in your database. But applied in the mapping scheme these characters constantly produce “fatal python errors”! To fix such a fatal mapping mistake you have to close the browser window and open it again. So, you will loose your changes if they are not saved. There’s no way to annul that error by going backwards in your browser! Please have a look at a
mapping example. |
|
5. Test MappingPlease press 'Test Mapping!' to execute a capability test as well as a scan and search test for ABCD 2.06. If you get the message. You can start a test search if you receive the message "No errors found!" during all three tests. Therefore, click on "QueryForms" and select "ABCD2 search". The following code should than be visible:
<filter> Please press "Submit" (on the top of the page) to send the query to your database. You will hopefully see some results in xml. Otherwise you should check the search key (A* searches for taxa beginning with A.) or change the debugging level for more detailed error messages. |
|